
理解KV Cache
你有没有想过为什么当和ChatGPT等大模型对话时,第一个词的生成需要等待一段时间,但后续的生成都非常顺利,一气呵成?这实际上可以归功于KV Cache的设计。
KV Cache其实是一个非常简单的设计,旨在解决大模型生成文本时的重复计算问题。
标准的推理过程
当大模型生成文本时,它需要看所有先前的tokens(在上下文长度之内的)以预测下一个token。一般地,它对每一个新token会重复相同的计算,可能会很慢。具体而言,在自注意力机制计算时,例如,对于第一个token,其输入嵌入要首先要与Wq、Wk、Wv相乘,得到q、k、v向量,然后(为简单起见,以不带掩码的注意力机制为例),每个q与其他所有的k相乘(在带掩码的注意力机制里,是每个q与自己的k和先前的k相乘,例如,q1只与k1相乘,q2与k1和k2相乘),得到注意力权重,所有的注意力权重soft经Softmax后再与v向量相乘,得到最终的上下文向量,如图所示:
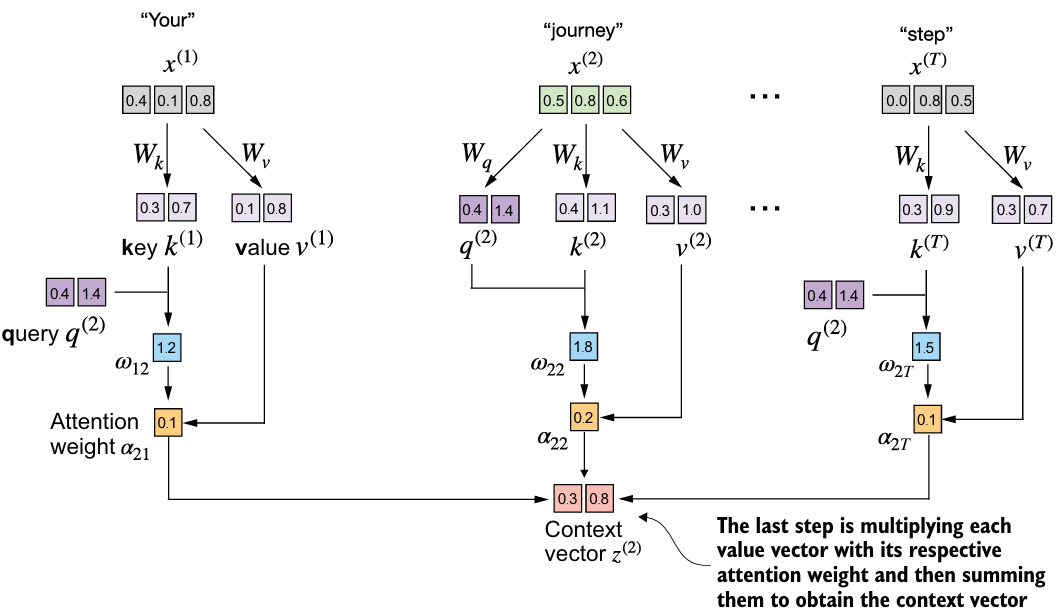
可以发现,之后的每个q都要与其他的k、v(在因果注意力中是与先前的k、v)进行乘法计算。
在实际的大模型中,一般都使用因果注意力或者叫带掩码的注意力机制,例如,q3要与k1、k2、k3和v1、v2、v3相乘,得到$\omega$3,既然如此,可以先把所有的k和v向量提前缓存好,然后在后续的计算中直接使用,而无需重复计算,这样可以大幅度节约推理的时间和成本。
KV Cache是怎么工作的?
- 第一次生成:当模型看见第一个输入时,它计算并保存它的k和v向量到cache中。
- 下一个词:对于每一个新词,模型检索存储的k和v向量,并把当前的k和v添加到cache中,而不是从头计算每一个k、v。
- 高效的Attention计算:对于新的Q,使用cached的K和V来计算输出。
- 更新输入:把生成的token加入到输入中,回到第二步,直到结束生成。
可以诠释为如下过程:
1 | Token 1: [K1, V1] ➔ Cache: [K1, V1] |
对比KV Cache和标准推理
| 特征 | 标准推理 | KV Cache |
|---|---|---|
| 每个词的计算 | 对于每个词,模型重复相同的计算 | 模型复用过去的计算以得到更快的结果 |
| 内存占用 | 在每一步使用更少的内存,但内存占用随着更长的文本增长 | 使用额外的内存来保存过去的信息,但保证计算高效 |
| 速度 | 随着文本长度变长而变慢,因为它重复工作 | 即使文本变长也能保持快速,因为避免了重复工作 |
| 效率 | 高计算开销,更慢的响应时间 | 更快更高效 |
| 处理长文本 | 艰难处理长文本,因为重复计算 | 非常适合处理长文本 |
- Title: 理解KV Cache
- Author: ZYX
- Created at : 2025-09-19 14:57:57
- Updated at : 2025-09-19 14:57:57
- Link: https://zyxzyx.top/理解KV Cache/
- License: This work is licensed under CC BY-NC-SA 4.0.