

-

Test Page
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub. Qu... -

LaTeX入门(二)
参考文章:Learn LaTeX in 30 minitues 学会使用LaTeX在LaTeX中加入数学LaTeX的优势之一是可以轻松编写数学表达式。LaTeX提供了两种写作模式以排版数学公式: 内联数学模式,用于撰写处于段落中的数学公式; 展示数学模式,用于撰写不是文本或段落中一部分的表达式,并排版在独立的行中。 内联数学模式示例: 12345\documentclass[12pt, ... -
LaTeX入门(一)
参考文章:Learn LaTeX in 30 minitues 什么是LaTeXLaTeX(读作:”LAY-tek” 或者 “LAH-tek”)是一种用于排版专业外观文档的工具。LaTeX与一些其他常用的文档生产应用如Word的操作方式十分不同:那些“所见即所得”(WYSIWYG)的工具提供用户交互性的页面,用户可以在里面输入和编辑文本或应用不同的样式。 LaTeX则正相反,你的文档是一个纯... -

“斯坦福小镇”论文调研
闻名一时的“斯坦福小镇”,源自斯坦福大学团队2023年4月7日发表的一篇论文:《Generative Agents: Interactive Simulacra of Human Behavior》,旨在通过大模型创建一个反应人类行为的人工社会。 论文地址:Arxiv PDF 开源代码:Github Smallville概要场景构建这篇工作构建了一个名为 Smallville 的小镇场景... -

理解KV Cache
你有没有想过为什么当和ChatGPT等大模型对话时,第一个词的生成需要等待一段时间,但后续的生成都非常顺利,一气呵成?这实际上可以归功于KV Cache的设计。 KV Cache其实是一个非常简单的设计,旨在解决大模型生成文本时的重复计算问题。 标准的推理过程当大模型生成文本时,它需要看所有先前的tokens(在上下文长度之内的)以预测下一个token。一般地,它对每一个新token会重复相... -
论文阅读情况
编号 日期 标题 发表日期 类型 论文&代码 概要 贡献 1 25.9.6 Generative Agents: Interactive Simulacra of Human Behavior【UIST’23】 23.4.7 多Agent模拟社会 ArxivGithub 用基本的自然语言描述来初始化智能体。以自然语言的方式存储智能体的“记忆流”。存储一定的记忆流后合成为更... -
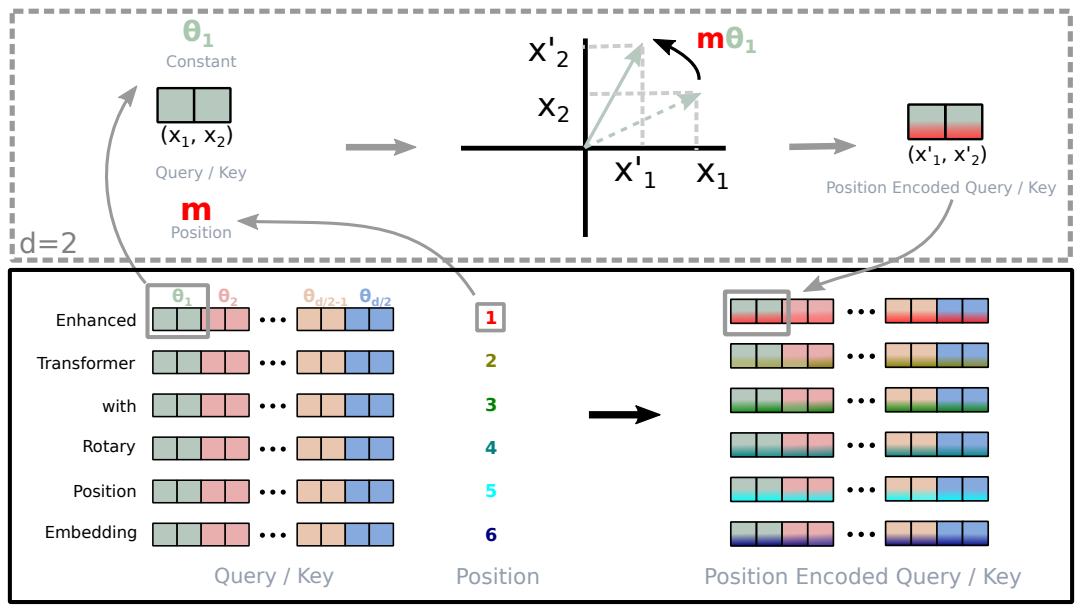
理解RoPE位置嵌入
大语言模型的第一步就是将数据处理成可以输入大模型的形式,即输入嵌入。这包含几个步骤,分别是: 使用分词器(如BPE)将输入文本划分为token 根据分词器的划分,构建token到token ID的双向映射 通过嵌入层,将token ID转换为嵌入向量(称为词元嵌入) 根据token在序列中的位置,创建位置嵌入 将3、4步得到的嵌入相加,得到输入大模型的输入嵌入 其他几个步骤都比较简单...
1